3. Algorithmes de recherche¶
Les ordinateurs passent la majorité de leur temps à chercher : ils cherchent des fichiers, ils cherchent des sites Web, ils cherchent des informations dans un site Web, ils cherchent votre compte lorsque vous vous loguez sur un site Web, ils cherchent des posts à vous montrer et des personnes à qui vous connecter. Nous allons commencer par estimer la complexité de deux algorithmes de recherche importants.
La complexité ne reflète pas la difficulté à implémenter un algorithme, comme on pourrait le croire, mais à quel point l’algorithme se complexifie au fur et à mesure que le nombre des entrées augmente. La complexité mesure le temps d’exécution d’un algorithme (ou sa rapidité) en termes du nombre d’instructions élémentaires exécutées en fonction de la taille des données.
Recherche linéaire¶
La manière la plus simple pour rechercher un élément dans un tableau (une liste en Python) consiste à parcourir le tableau et à comparer l’élément recherché à tous les éléments du tableau :
# Algorithme de recherche linéaire
Tableau Eléments # données stockées dans un tableau (une liste en Python)
n ← longueur(Eléments) # la variable n contient le nombre d'éléments
elément_recherché ← entrée # l'élément recherché en tant que paramètre de l'algorithme
i ← 0 # index pour parcourir la liste
Répéter Pour i = 1 à n
si Eléments[i] == élément_recherché
Retourner « Oui »
Fin Répéter
Retourner « Non »
Quelle est la complexité de cet algorithme de recherche linéaire ? Pour répondre à cette question, il faut estimer le nombre d’instructions élémentaires nécessaires pour rechercher un élément dans un tableau. Ce nombre dépend naturellement de la taille du tableau n : plus le nombre d’éléments dans le tableau est grand, plus on a besoin d’instructions pour retrouver un élément.
Supposons que le tableau contienne 10 éléments. Pour trouver l’élément recherché, il faut au moins deux instructions par élément du tableau : une instruction pour accéder à l’élément du tableau (ou Elements[i]) et une autre instruction pour le comparer à élément_recherché. Dans le cas du tableau à 10 éléments, cet algorithme prendrait 20 instructions élémentaires, 2 (instructions) multiplié par le nombre d’éléments dans le tableau. Mais si le tableau contient 100 éléments, le nombre d’instructions élémentaires monte à 200. De manière générale, si le nombre d’éléments dans le tableau est n, cela prend 2n instructions pour le parcourir et pour comparer ses éléments.
Cette estimation n’est pas exacte. Nous n’avons pas pris en compte les instructions élémentaires qui permettent d’incrémenter i et de vérifier si i == longueur(Nombres). Lorsqu’on prend en compte ces 2 instructions supplémentaires liées à l’utilisation de i, le nombre d’instructions passe de 200 à 400 (ce qui correspond à 4n). Il faut également y ajouter les 4 instructions d’initialisation avant la boucle, plus l’instruction de retour à la fin de l’algorithme, ce qui fait monter le nombre d’instructions de 400 à 405 (4n + 5). Attention, le nombre exact peut être différent, car il dépend de l’implémentation sur la machine. Mais, ce qui nous intéresse ici n’est pas tant le nombre exact d’instructions, si c’est 205 ou 410 ou 815. Ce qui nous intéresse ici est plutôt l’ordre de grandeur de l’algorithme ou comment le nombre d’instructions élémentaires grandit avec la taille du tableau n.
Cet algorithme est de complexité linéaire. Une complexité linéaire implique que le nombre d’instructions élémentaires croît linéairement en fonction du nombre d’éléments des données : cn + a, ou c et a sont des constantes. Dans ce cas précis, c vaut 4 et a vaut 5. Si le tableau contient 10 éléments, il faut environ 45 instructions ; pour 100 éléments il faut environ 405 instructions ; pour 1000 éléments il faut environ 4005 instructions et ainsi de suite. Le nombre d’instructions grandit de manière linéaire en fonction de la taille des données n, et cette relation est représentée par une ligne lorsqu’on la dessine (voir la figure ci-dessous).
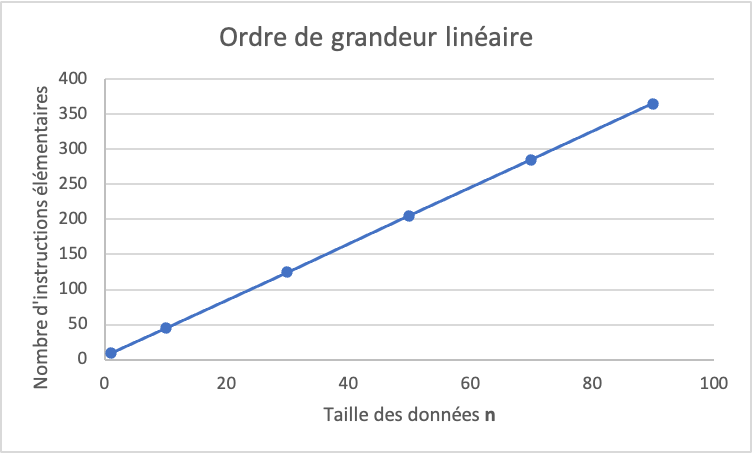
Complexité linéaire. La complexité de l’algorithme de recherche linéaire, comme son nom l’indique, est linéaire. La relation entre la taille du tableau n et le nombre d’instructions nécessaires pour retrouver un élément dans ce tableau représente une ligne.¶
Exercice 2.0. Compter jusqu’à n
Ecrire un algorithme qui affiche tous les nombres de 1 à n.
Combien d’instructions élémentaires sont nécessaires lorsque n vaut 100 ?
Quel est la complexité de cet algorithme ?
Solution 2.0. Compter jusqu’à n
Cliquer ici pour voir la réponse
Variable n : numérique
Variable i : numérique
Répéter Pour i = 1 à n
Afficher(i)
Fin Pour
L’initialisation des variables n et i compte pour 2 instructions élémentaires. Chaque passage de la boucle correspond à trois instructions élémentaires : 1 instruction qui affiche i, 1 instruction qui incrémente i de 1 et finalement une instruction qui compare i à n (pour savoir si la boucle s’arrête ou si elle continue). Le total d’instructions élémentaires pour le cas où n vaut 100 est 3 * 100 + 2 ou 302 instructions élémentaires.
Il faut se rendre compte que cette estimation du nombre d’instructions élémentaires est approximatif, et non pas exact. Par exemple, l’instruction élémentaire Afficher(i) englobe certainement plusieurs instructions à l’exécution et prend de plus en plus de temps à mesure que i grandit (affiche de plus en plus de caractères).
La complexité (ou l’ordre de grandeur) de cet algorithme est linéaire, comme illustré dans ce graphique :
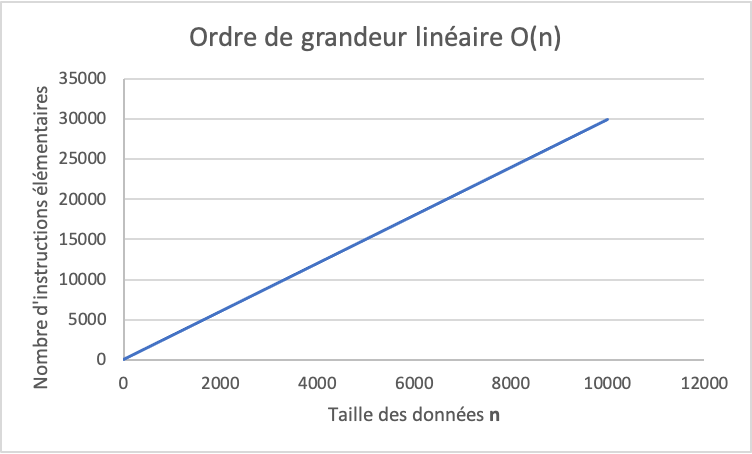
Exercice 2.1. Compter par pas de 2
Ecrire un algorithme qui affiche tous les nombres pairs de 1 à n.
Combien d’instructions élémentaires sont nécessaires lorsque n vaut 100 ?
Quel est la complexité de cet algorithme ?
Solution 2.1. Compter par pas de 2
Cliquer ici pour voir la réponse
Variable n : numérique
Variable i : numérique
Répéter Pour i = 2 à n, par pas de 2
Afficher(i)
Fin Pour
La seule ligne qui change par rapport à la solution de l’exercice précédent est l’incrément de la boucle par pas de 2.
L’initialisation des variables i et n compte pour 2 instructions élémentaires. Chaque passage de la boucle correspond à trois instructions élémentaires : 1 instruction qui affiche i, 1 instruction qui incrémente i de 2 et finalement 1 instruction qui compare i à n (pour savoir si la boucle s’arrête ou si elle continue). Pour le cas où n vaut 100, la boucle sera parcourue 50 fois (par pas de 2). Le total d’instructions élémentaires est donc 3 * 50 + 2 ou 152 instructions élémentaires.
La complexité (ou l’ordre de grandeur) de cet algorithme est également linéaire, comme illustré dans le graphique. Il faut noter que l’ordre de grandeur est le même que pour l’exercice précédent, seule la vitesse de croissance change.
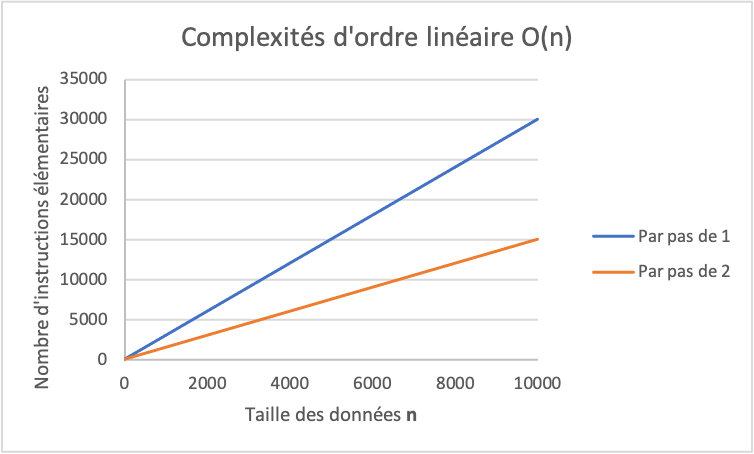
La différence de croissance se cache dans la constante c de l’ordre de grandeur cn + a. La valeur de c dans l’exercice précédent est supérieure à la valeur de c dans cet exercice. Dans un premier temps, on peut ignorer la valeur de cette constante c. Cependant elle peut devenir importante lorsque l’on doit comparer des algorithmes du même ordre entre eux.
Exercice 2.2. Recherche linéaire🔌
Programmer l’algorithme de recherche linéaire en Python. Rechercher une valeur entre 1 et 1000000 dans un tableau qui contient les valeurs allant de 1 à 1000000.
Pour quelle valeur l’algorithme est le plus rapide ? Pour quelle valeur l’algorithme est le plus lent ? Indice : utiliser le module time pour chronometrer le temps d’exécution.
Est-ce que ce résultat vaut si les éléments du tableau ne sont pas dans l’ordre ? Essayer en utilisant la fonction shuffle() du module random.
Solution 2.2. Recherche linéaire🔌
Pour aller plus loin
Pour décrire mathématiquement les ordres de complexité, on utilise la notation « Grand O ». Pour dire qu’un ordre de complexité est linéaire, on écrit par exemple qu’il est O(n).
2.2. Recherche binaire¶
Matière à réfléchir. Le dictionnaire
Comment faites-vous pour rechercher un mot dans un dictionnaire ?
Utilisez-vous l’algorithme de recherche linéaire, parcourez-vous tous les éléments un à un ?
Quelle propriété du dictionnaire nous permet d’utiliser un autre algorithme de recherche que l’algorithme de recherche linéaire ?
Si on doit rechercher un élément dans un tableau qui est déjà trié, l’algorithme de recherche linéaire n’est pas optimal. Dans le cas de la recherche d’un mot dans un dictionnaire, la recherche linéaire implique que l’on va parcourir tous les mots du dictionnaire dans l’ordre, jusqu’à trouver le mot recherché. Mais nous ne recherchons pas les mots dans un dictionnaire de la sorte. Nous exploitons le fait que les mots du dictionnaire sont triés dans un ordre alphabétique. On commence par ouvrir le dictionnaire sur une page au hasard et on regarde si le mot recherché se trouve avant ou après cette page. On ouvre ensuite une autre page au hasard dans la partie retenue du dictionnaire. On appelle cette méthode la recherche binaire (ou la recherche dichotomique), car à chaque itération elle divise l’espace de recherche en deux. En effet, à chaque nouvelle page ouverte, nous éliminons environ la moitié du dictionnaire qui nous restait à parcourir. Voici une description de l’algorithme de recherche binaire :
# Algorithme de recherche binaire
Tableau Eléments # les données du tableau (liste en Python) sont triées
n ← longueur(Eléments) # la variable n contient le nombre d'éléments
elément_recherché ← entrée # l'élément recherché en tant que paramètre de l'algorithme
trouvé ← Faux # indique si l'élément à été retrouvé
index_début ← 0 # au début on cherche dans tout le tableau
index_fin ← n # au début on cherche dans tout le tableau
i ← 0 # index pour parcourir la liste
# tant que l'élément n'est pas trouvé et que le sous-tableau retenu n'est pas vide
Tant que trouvé != Vrai et n > 0 :
# on identifie le milieu du sous-tableau retenu
index_milieu = (index_fin - index_début)/2 + index_début
# si l'élément recherché correspond à l'élément du milieu du sous-tableau retenu
if Eléments[index_milieu] == elément_recherché :
trouvé = Vrai
else :
# si l'élément du milieu est plus grand que l'élément recherché
# on retient la première moitié comme sous-tableau
if Eléments[index_milieu] > elément_recherché :
index_fin = index_milieu
# si l'élément du milieu est plus petit que l'élément recherché
# on retient la deuxième moitié comme sous-tableau
else :
index_début = index_milieu+1
# calcule le nombre d'éléments du sous-tableau retenu
n = index_fin - index_début
Fin Tant que
Retourner trouvé
Prenons le temps d’étudier cet algorithme. Que fait-il ? La boucle Tant que permet de parcourir le tableau Eléments et d’y rechercher elément_recherché tant qu’il n’est pas trouvé (tant que trouvé != Vrai). A la première itération (au premier passage dans la boucle, on vérifie si l’élément au milieu du tableau Eléments n’est justement pas l’élément recherché. Les éléments de la liste étant triés, si l’élément au milieu du tableau est plus grand que l’élément recherché, cela indique que elément_recherché se trouve dans la première partie du tableau. Si l’élément au milieu du tableau est plus petit que l’élément recherché, cela indique que l’élément recherché se trouve au contraire dans la deuxième moitié du tableau. Pour la suite de la recherche, on retient soit la première, soit la deuxième moitié du tableau, selon si l’élément recherché est plus grand ou plus petit que l’élément du milieu. A chaque prochaine itération (à chaque passage dans la boucle), on vérifie si l’élément au milieu du nouveau sous-tableau retenu n’est pas l’élément recherché.
Dans la recherche linéaire, chaque passage de la boucle permettait de comparer un élément à l’élément recherché et l’espace de recherche diminuait seulement de 1 (l’espace de recherche correspond aux nombre d’emplacements encore possibles). Dans la recherche binaire, chaque passage de la boucle divise l’espace de recherche par deux et nous n’avons besoin de parcourir plus qu’une moitié (de la moitié, de la moitié, de la moitié, etc.) du tableau.
Le nombre d’étapes nécessaires pour rechercher un élément dans un tableau de taille 16 de façon dichotomique correspond donc au nombre de fois que le tableau peut être divisé en 2 et correspond à 4 (comme on peut le voir sur la figure ci-dessous), parce que :
16 / 2 / 2 / 2 / 2 = 1 donc
2 * 2 * 2 * 2 = 16 ou
24 = 16
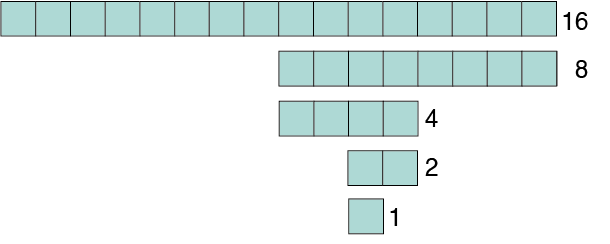
Exemple de parcours d’un tableau trié. Seulement 4 étapes sont suffisantes pour parcourir un tableau trié de 16 éléments à la recherche d’un élément qui se trouve à la onzième position. A chaque étape, l’espace de recherche est divisé par 2. Si le tableau n’était pas trié, 11 étapes seraient nécessaires (on doit vérifier chaque élément dans l’ordre).¶
Si on généralise, le nombre d’étapes x nécessaires pour parcourir un tableau de taille n est :
2x = n par conséquent
x = log2(n) ~ log(n) la simplification peut être faite car l’ordre de grandeur est le même
La complexité de l’algorithme de recherche binaire est donc logarithmique, lorsque n grandit nous avons besoin de log(n) opérations. La figure ci-dessous permet de comparer les ordres de grandeur logarithmique et linéaire. On remarque qu’un algorithme de complexité logarithmique est beaucoup plus rapide qu’un algorithme de complexité linéaire, car il a besoin de beaucoup moins d’instructions élémentaires pour trouver une solution.
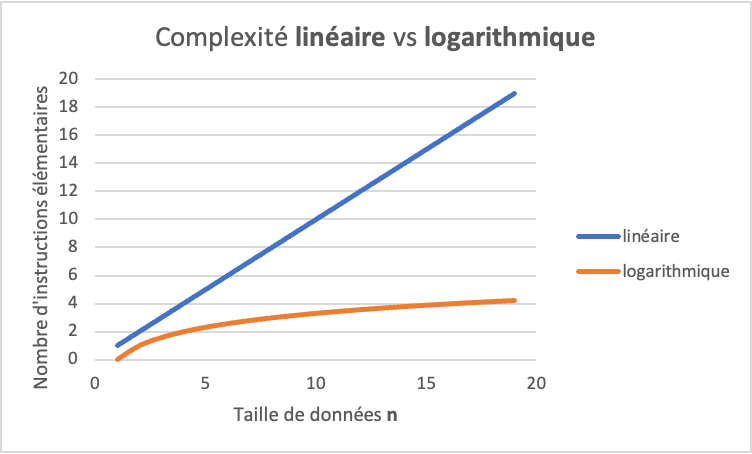
Comparaison de complexités logarithmique et linéaire. Un algorithme de complexité logarithmique est plus rapide qu’un algorithme de complexité linéaire.¶
L’algorithme de la recherche binaire se base sur une stratégie algorithmique de résolution de problèmes très efficace, que l’on appelle la stratégie « diviser pour régner ». Cette stratégie qui consiste à :
Diviser : décomposer le problème initial en sous-problèmes ;
Régner : résoudre les sous-problèmes ;
Combiner : calculer une solution au problème initial à partir des solutions des sous-problèmes.
Les sous-problèmes étant plus petits, ils sont plus faciles et donc plus rapides à résoudre. Les algorithmes de ce type en plus d’être efficaces, se prêtent à la résolution en parallèle (par exemple sur des multiprocesseurs).
Exercice 2.3 Recherche binaire 🔌
Programmer l’algorithme de recherche binaire en Python. Rechercher une valeur entre 0 et 100 dans un tableau qui contient les valeurs allant de 0 à 100.
Pour quelle valeur l’algorithme est le plus rapide ? Pour quelle valeur l’algorithme est le plus lent ? Indice : mettre le mode verbose pour afficher ce que fait l’algorithme.
Est-ce qu’on peut utiliser l’algorithme de recherche binaire si le tableau n’est pas trié ? Essayer avec la fonction shuffle() du module random.
Solution 2.3. Recherche binaire 🔌
Exercice 2.4. Recherche linéaire versus binaire 🔌
Reprendre les programmes de recherche linéaire et recherche binaire en Python et les utiliser pour rechercher un élément dans un tableau à 100 éléments : quel algorithme est le plus rapide ?
Augmenter la taille du tableau à 1000, 10000, 100000, 1000000 et 1000000. Rechercher un élément avec vos deux programmes. Quel algorithme est plus rapide ? Est-ce significatif ?
Est-ce que un million vous semble être un grand nombre pour une taille de données ?
Exercice 2.4. Recherche linéaire versus binaire 🔌
Exercices¶
Exercice 2.5. Recherche binaire aléatoire 🔌
Modifier votre programme de recherche binaire : au lieu de diviser l’espace de recherche exactement au milieu, le diviser au hasard. Cette recherche avec une composante aléatoire s’apparente plus à la recherche que l’on fait lorsque l’on cherche un mot dans le dictionnaire.
Ai-je compris ?
Je sais que la complexité temporelle donne une indication sur la vitesse d’un algorithme, en mesurant le nombre d’instructions élémentaires.
Je sais qu’un algorithme de complexité linéaire est plus lent qu’un algorithme de complexité logarithmique.
Je peux utiliser la stratégie « diviser pour régner » pour rechercher rapidement avec l’algorithme de recherche binaire.