2. Complexité des algorithmes¶
Matière à réfléchir III
On souhaite comparer deux algorithmes qui permettent de résoudre le même problème, afin d’utiliser l’algorithme qui permet de résoudre le problème plus rapidement. Mais comment pourrait‑on calculer la vitesse d’un algorithme ?
Principe de complexité¶
Nous avons vu dans la section Algorithmes de tri que certains algorithmes de tri étaient plus rapides que d’autres. Il est important lorsqu’on utilise un algorithme de nous préoccuper de son efficacité. Mais comment pourrait-on calculer la vitesse d’un algorithme ?
Est-ce qu’on peut utiliser la taille de l’algorithme pour prédire le temps qu’il va prendre à s’exécuter ? En d’autres termes, est-ce qu’un algorithme de 10 lignes est toujours plus lent qu’un algorithme de 5 lignes ? Nous avons vu que l’algorithme infini du chapitre précédent est très court (seulement 5 lignes), mais en théorie il ne s’arrête jamais. Une boucle rallonge le code de seulement 2 lignes, mais rallonge le temps d’exécution de manière bien plus significative.
On pourrait croire qu’il suffit de programmer un algorithme et de chronométrer le temps que ce programme prend à s’exécuter. Cette métrique est problématique, car elle ne permet pas de comparer différents algorithmes entre eux lorsqu’ils sont exécutés sur différentes machines. Un algorithme lent implémenté sur une machine dernière génération pourrait prendre moins de temps à s’exécuter qu’un algorithme rapide implémenté sur une machine datant d’une dizaine d’années.
Pour mesurer le temps d’exécution (ou la vitesse) d’un algorithme, il nous faut un critère plus objectif : le nombre d’instructions élémentaires. De manière formelle et rigoureuse, on ne parle pas d’efficacité, mais plutôt de la complexité d’un algorithme, qui est en fait contraire à son efficacité. L’analyse de la complexité d’un algorithme étudie la quantité de ressources (par exemple de temps) nécessaires à l’exécution de cet algorithme.
Le saviez-vous ?
Nous allons surtout étudier la complexité des algorithmes en rapport avec le temps. Mais la complexité d’un algorithme peut également être calculée en rapport avec toutes les ressources qu’il utilise, par exemple des ressources d’espace en mémoire ou de consommation d’énergie.
Recherche linéaire¶
Nous allons tenter ici d’estimer le nombre d’instructions élémentaires nécessaire pour rechercher un élément dans un tableau (liste en Python). La manière la plus simple pour rechercher un élément dans un tableau consiste à parcourir le tableau et à comparer tous ses éléments avec l’élément recherché :
# Algorithme de recherche linéaire
Tableau Eléments : numérique
Variable n : longueur(Eléments)
Variable élément_recherché : numérique
Variable i : numérique
Répéter Pour i = 1 à n
si Eléments[i] == élément_recherché
Retourner « Oui »
Fin Pour
Retourner « Non »
Supposons que le tableau contient 10 éléments. Pour trouver l’élément recherché, il faut au moins deux instructions : une instruction qui accède un élément du tableau ou Elements[i] et une autre instruction qui le compare à élément_recherché. Dans le cas du tableau à 10 éléments, cet algorithme prendrait 20 instructions élémentaires. Mais si le tableau contient 100 éléments, le nombre d’instructions élémentaires monte à environ 200. De manière générale, si le nombre d’éléments dans le tableau est n, et cela prend 2*n instructions pour parcourir et comparer ses éléments.
Cette estimation n’est pas exacte. Nous n’avons pas pris en compte les instructions élémentaires qui permettent d’incrémenter i et de vérifier si i == longueur(Nombres). Lorsqu’on prend en compte ces 2 instructions liées à i, le nombre d’instructions passe de 200 à 400. Ce qui nous intéresse ici n’est pas le nombre exact d’instructions, 200 ou 400, mais plutôt son ordre de grandeur ou comment ce nombre d’instructions élémentaires grandit avec n. L’algorithme ici est d’ordre O(n) ou linéaire.
Un ordre de grandeur linéaire implique que le nombre d’instructions élémentaires de l’algorithme croît linéairement en fonction du nombre d’éléments des données : c*n+a, ou c est une constante . Dans ce cas précis, c vaut 4. La constante a vaut 5 et correspond aux instructions d’initialisation avant la boucle plus l’instruction de retour à la fin. Si le tableau contient 10 éléments, il faut environ 45 instructions ; pour 100 éléments il faut environ 405 instructions ; pour 1000 éléments il faut environ 4005 instructions et ainsi de suite. Le nombre d’instructions grandit de manière linéaire en fonction de la taille des données n.
Exercice 1 : affichage des entiers ✏️📒
Ecrire un algorithme qui affiche tous les nombres de 1 à n.
Combien d’instructions élémentaires sont exécutées pour n=100 ? Quel est l’ordre de grandeur de cet algorithme ?
Solution
Cliquer ici pour voir la réponse
Variable n : numérique
Variable i : numérique
Répéter Pour i = 1 à n
Afficher(i)
Fin Pour
L’initialisation des variables n et i compte pour 2 instructions élémentaires. Chaque passage de la boucle correspond à trois instructions élémentaires : 1 instruction qui affiche i, 1 instruction qui incrémente i de 1 et finalement une instruction qui compare i à n (pour savoir si la boucle s’arrête ou si elle continue). Le total d’instructions élémentaires pour le cas où n vaut 100 est 3*100+1 ou 301 instructions élémentaires.
Il faut se rendre compte que ce nombre estimé d’instructions élémentaires est approximatif, et non pas exact. Par exemple, l’instruction élémentaire Afficher(i) n’est certainement implémentée avec une seule instruction à l’exécution et prend de plus en plus de temps à mesure que i grandit.
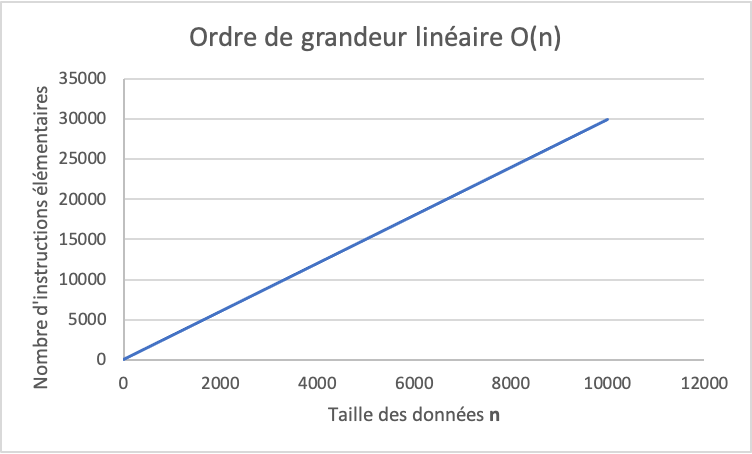
L’ordre de grandeur est O(n) ou linéaire, comme illustré dans ce graphique :
Exercice 2 : affichage des nombres pairs ✏️📒
Ecrire un algorithme qui affiche tous les nombres pairs de 1 à n.
Combien d’instructions élémentaires sont exécutées pour n=100 ? Quel est l’ordre de grandeur de cet algorithme ?
Solution
Cliquer ici pour voir la réponse
Variable n : numérique
Variable i : numérique
Répéter Pour i = 2 à n, par pas de 2
Afficher(i)
Fin Pour
Notez que la seule ligne de code qui change par rapport à la solution de l’exercice précédent est l’incrément de la boucle par pas de 2.
L’initialisation de la variable i compte pour 1 instruction élémentaire. Chaque passage de la boucle correspond à trois instructions élémentaires : 1 instruction qui affiche i, 1 instruction qui incrémente i de 2 et finalement une instruction qui compare i à n (pour savoir si la boucle s’arrête ou si elle continue). Pour la cas où n vaut 100, la boucle sera parcourue 50 fois. Le total d’instructions élémentaires est donc 3*50+1 ou 151 instructions élémentaires.
L’ordre de grandeur est O(n) ou linéaire, comme illustré dans ce graphique :
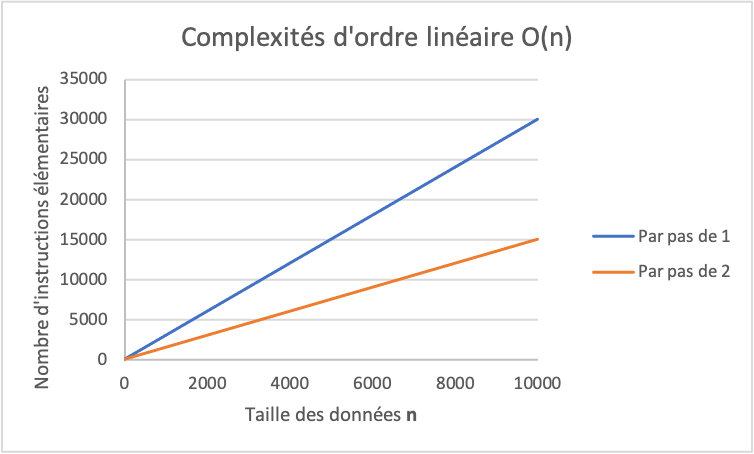
Notez que l’ordre de grandeur est le même que pour l’exercice précédent, seule la vitesse de croissance change.
Cette différence de croissance se cache dans la constante c de l’ordre de grandeur O(cn + a). La valeur de c dans l’exercice précédent est supérieure à la valeur de c dans cet exercice. Dans un premier lieu, on ne se préoccupe pas de cette constante c et on s’intéresse à l’ordre de grandeur général ou tout simplement O(n). Par contre, lorsque l’on doit comparer des algorithmes du même ordre entre eux, il faut s’intéresser à la valeur de cette constante et la calculer.
Matière à réfléchir IV
Comment faites-vous pour rechercher un mot dans un dictionnaire ?
Avez-vous utilisé l’algorithme de recherche linéaire qui parcourt tous les éléments un par un ?
Quelle propriété du dictionnaire nous permet d’utiliser un autre algorithme de recherche que l’algorithme de recherche linéaire ?
Recherche binaire¶
Si on doit rechercher un élément dans un tableau déjà trié, l’algorithme de la recherche linéaire n’est pas optimal. Dans le cas d’un dictionnaire, lorsque l’on recherche un mot, on ne va pas parcourir tous les mots du dictionnaire dans l’ordre. Nous exploitons le fait que les mots du dictionnaire sont triés dans un ordre alphabétique. On commence par ouvrir le dictionnaire sur une page au hasard et on regarde si le mot recherché se trouve avant ou après cette page. On ouvre ensuite une autre page au hasard dans la partie avant ou après du dictionnaire. On appelle cette méthode la recherche binaire (ou recherche dichotomique), car concrètement elle divise l’espace de recherche par deux à chaque itération (à chaque nouvelle page ouverte, nous éliminons environ la moitié de l’espace de recherche) :
# Algorithme de recherche binaire
Tableau Eléments : numérique # les données du tableau sont triées
Variable n : longueur(Eléments)
Variable elément_recherché : numérique
Variable trouvé : Faux
Variable i : numérique
Tant que trouvé != Vrai et n > 0 :
indice_milieu = partie_entière(n/2)
if Eléments[indice_milieu] == elément_recherché :
trouvé = Vrai
else :
if Eléments[indice_milieu] > elément_recherché :
Eléments = Eléments[:indice_milieu]
else :
Eléments = Eléments[indice_milieu+1:]
n = longueur(Eléments)
Fin Tant que
Retourner trouvé
Prenez le temps d’étudier cet algorithme. Que fait-il ? La boucle Tant que permet de rechercher elément_recherché à l’intérieur d’Eléments tant qu’il n’est pas trouvé (trouvé != Vrai). A chaque itération (à chaque passage dans la boucle), on vérifie si l’élément au milieu du tableau Eléments n’est pas l’élément recherché. Si l’ élément au milieu du tableau est plus grand que l’élément recherché, cela indique que elément_recherché se trouverait dans la première partie du tableau, les éléments étant triés. Si cet élément du milieu du tableau est plus petit que l’élément recherché, cela indique que l’élément recherché se trouverait au contraire dans la deuxième partie du tableau.
Dans la recherche linéaire, chaque passage de la boucle permet de comparer un élément à l’élément recherché et l’espace de recherche diminue seulement de 1. A chaque itération de la recherche binaire, l’espace de recherche est divisé par deux et nous n’avons besoin de parcourir plus qu’une moitié du tableau.
Le nombre d’étapes nécessaires pour rechercher dans un tableau de taille 16 de façon dichotomique est donc le nombre de fois que le tableau peut être divisé en 2 et correspond à 4 (voir la figure ci-dessous) parce que :
16 / 2 / 2 / 2 / 2 = 1, donc 16 = 2 * 2 * 2 * 2 ou 16 = 24
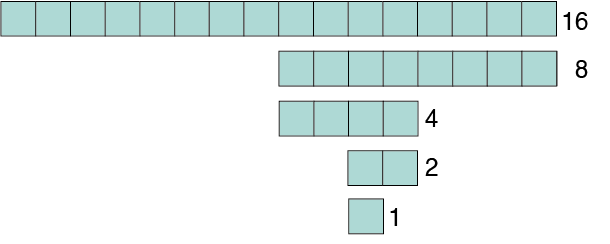
Seulement 4 étapes sont suffisantes pour parcourir un tableau trié de 16 éléments à la recherche d’un élément. A chaque étape, l’espace de recherche est divisé par 2
De manière générale, le nombre d’étapes x nécessaires pour parcourir un tableau de taille n est :
2 * x = n
x = log2(n) ~ log(n) # simplification : même ordre de grandeur
L’ordre de croissance de la recherche binaire est donc O(log(n)). La figure ci-dessous permet de comparer la croissance de n versus log(n). Un algorithme de complexité O(log(n)) est beaucoup plus rapide qu’un algorithme de complexité linéaire O(n). La lettre O ici est pour « Ordre ».
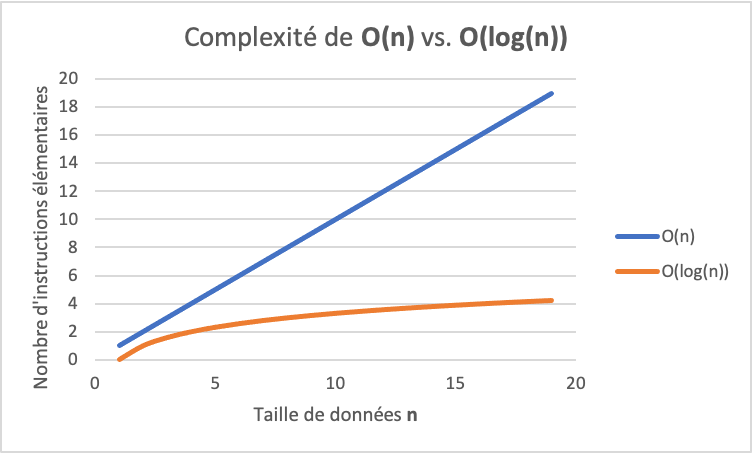
Un algorithme avec un ordre de complexité logarithmique est plus rapide qu’un algorithme de complexité linéaire
Exercice 3 : recherche linéaire et binaire 🔌
Programmer les algorithmes de recherche linéaire et binaire en Python.
Rechercher une valeur entre 1 et 100 dans un tableau trié qui contient des valeurs de 1 à 100.
Utiliser vos deux programmes pour rechercher un élément : quel algorithme est le plus rapide ?
Augmenter la taille du tableau à 10000. Rechercher un élément vos deux programmes. Quel algorithme est plus rapide ? Est-ce significatif ? Est-ce que 10000 vous semble être un grand nombre ?
Est-ce qu’on peut utiliser l’algorithme de recherche binaire si le tableau n’est pas trié ? Essayez.
Solution
Pour aller plus loin
Modifier votre programme de recherche binaire : au lieu de diviser l’espace de recherche exactement au milieu, le diviser au hasard. Cette recherche avec une composante randomisée s’apparente plus à la recherche que l’on fait lorsque l’on cherche un mot dans le dictionnaire.
Rechercher une valeur avec les deux versions de recherche binaire. Quel algorithme est plus rapide ?
Rechercher plusieurs valeurs avec les deux versions de recherche binaire. Est-ce que c’est toujours le même algorithme qui est le plus rapide ?
Quel algorithme est plus rapide en moyenne ?
Rechercher une valeur avec la nouvelle version randomisée de recherche binaire. Exécuter le programme plusieurs fois. Est-ce que ça prend toujours le même temps ? Pourquoi ?
Tri par sélection¶
Pour rappel, le tri par sélection parcourt le tableau à la recherche du plus petit élément, et ce pour tous les éléments du tableau. Afin de trouver le plus petit élément du tableau, il faut commencer par parcourir toute la liste. Cette opération prend cn instructions : c instructions pour l’accès et la comparaison des éléments du tableau, multiplié par le nombre d’éléments. Il faut ensuite trouver le plus petit élément des éléments restants n-1, et ainsi de suite. Concrètement, on se retrouve avec la somme suivante :
cn + c(n-1) + c(n-2) + … + c(n/2+1) + c(n/2) + … + 3c + 2c + c
Si on réarrange l’ordre des termes on obtient cette somme d’instructions :
cn + c + c(n-1) + 2c + c(n-2) + 3c + … + c(n/2+1) + c(n/2)
On groupe ensuite les termes deux par deux :
(cn + c) + (c(n-1) + 2c) + (c(n-2) + 3c) + … + (c(n/2+1) + c(n/2))
On obtient ainsi plusieurs fois le même terme :
c(n+1) + c(n+1) + c(n+1) + … + c(n+1)
Nous avons commencé par n termes, que l’on a combinés deux par deux. On se retrouve donc avec la moitié des termes ou n/2 :
c(n+1)*n/2
Le terme qui divise par 2 peut être absorbé dans la constante c (la valeur de celle-ci changerait). Finalement, on ajoute une constante a pour prendre en compte le nombre d’instructions qui ne dépendent pas de la taille des données (p. ex : initialisations au début de l’algorithme) :
c’(n+1)*n + a = c’n2 + c’n + a ou c’= c/2
Quand n est très grand, le terme qui domine cette somme est le c’n2. Comme ce qui nous intéresse est l’ordre de grandeur de la croissance, la complexité du tri par sélection est O(n2) ou quadratique.
Exercice 4 : complexité et tri par insertion ✏️📒
Quelle est la complexité de l’algorithme de tri par insertion ? En d’autres termes, si le tableau contient n éléments, combien faut-il d’instructions pour trier ce tableau ?
Solution
Exercice 5 : complexité et tri à bulles ✏️📒
Quelle est la complexité de l’algorithme de tri à bulles ?
Solution
Tri rapide¶
Tous les algorithmes de tri vus dans le chapitre précédent sont des algorithmess d’ordre quadratique ou de complexité O(n2). Il existe d’autres algorithmess de tri qui sont bien plus rapides. Nous allons voir un algorithme de tri tellement rapide, qu’on lui a donné le nom de tri rapide.
On commence par définir un élément pivot : cet élément peut être le premier élément du tableau, l’élément du milieu, le dernier élément ou encore un élément au hasard. Supposons ici que l’élément pivot est le dernier élément du tableau. Une fois que l’on a défini l’élément pivot, on met tous les éléments qui sont plus petits que le pivot à sa gauche et tous les éléments qui sont plus grands que le pivot à droite de celui‑ci (voir la deuxième ligne de la Figure Tri rapide ci-dessous).
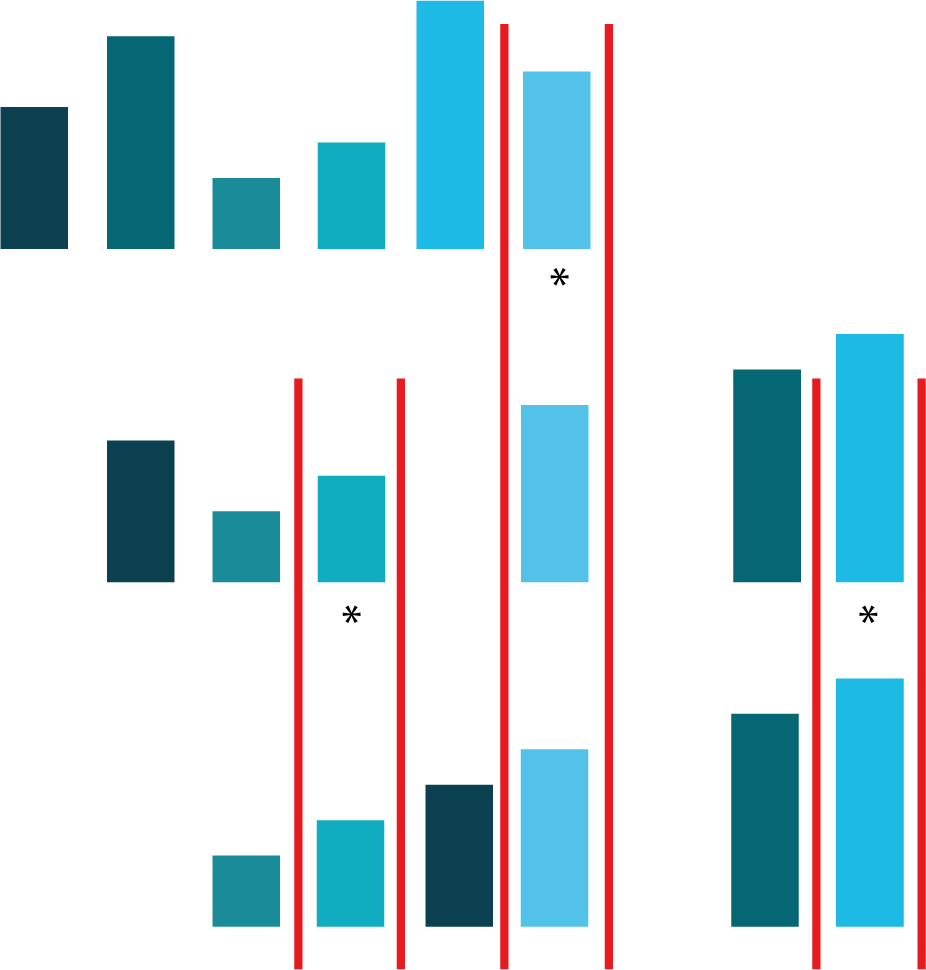
Tri rapide. Illustration du tri rapide sur le même set de données que celui utilisé pour illustrer les algorithmes de tri vus au chapitre précédent. L’élément pivot est le dernier élément des tableaux à trier
Après la répartition des éléments autour de l’élément pivot en fonction de leur taille, on se retrouve avec deux tableaux non triés, un tableau à chaque côté de l’élément pivot. On continue de traiter ces deux tableaux de la même manière que le tableau initial. On sélectionne pour chaque tableau, celui de gauche et celui de droite, un nouvel élément pivot (le dernier élément du tableau). Pour chaque nouvel élément pivot, on met à gauche les éléments du tableau qui sont plus petits que le pivot. Les éléments qui sont plus grands que le pivot se retrouvent à sa droite. On agit de la sorte jusqu’à ce qu’il ne reste plus que des tableaux à 1 élément.
Intéressons‑nous maintenant à la complexité de cet algorithme. A chaque étape (chaque ligne dans la Figure Tri rapide ci-dessus), on compare tout au plus n éléments avec les éléments pivots. Mais combien d’étapes faut-il pour que cet algorithme se termine ?
A chaque étape de l’algorithme, l’espace de recherche est divisé par 2 (dans le meilleur des cas). Nous avons vu dans l’algorithme de la recherche binaire que lorsqu’on divise l’espace de recherche par deux, on obtient une complexité de O(log(n)). Pour obtenir le nombre total d’instructions élémentaires on multiplie le nombre maximal de comparaisons par étape n avec le nombre d’étapes log(n). Donc l’ordre de complexité du tri rapide est en moyenne O(nlog(n)).
Comparons maintenant les différentes croissances des ordres de complexité vus jusqu’ici (voir la Figure ci-dessous). On voit bien que moins d’instructions élémentaires sont nécessaires pour le tri rapide d’ordre O(nlog(n)) que pour le tri à sélection d’ordre O(n2).
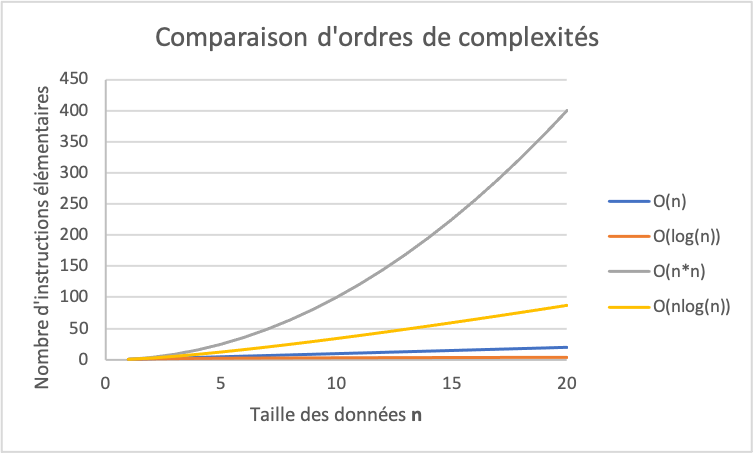
Comparaison des ordres de complexité vus jusqu’ici. Plus le nombre d’instructions élémentaires grandit avec la taille des données, plus l’algorithme est lent
Matière à réfléchir V
Appliquer le tri par rapide à un tableau déjà trié. Est-ce que le tri rapide est plus lent ou plus rapide que dans le cas moyen ?
Quelle est la complexité du tri rapide dans ce cas ? Est-ce que le choix du pivot est important dans ce cas ?
Mêmes questions pour le tri par insertion.
Tri fusion¶
Un autre algorithme de complexité O(nlog(n)) est le tri fusion. L’algorithme se base sur l’idée qu’il est difficile de trier beaucoup d’éléments, mais qu’il est très facile de trier deux éléments et de fusionner deux tableaux déjà triés.
L’algorithme commence par une phase de division : on découpe le tableau en deux, jusqu’à arriver à uniquement des tableaux à 1 élément (voir la Figure Diviser ci-dessous). Le nombre d’étapes nécessaires pour découper le tableau en tableaux à 1 élément en divisant toujours les tableaux en deux est log(n).
La deuxième phase consiste à fusionner les petits tableaux. On commence par fusionner les éléments 1 à 1, dans un ordre qui dépend de leur taille. Il suffit d’assembler les deux éléments du plus petit au plus grand (voir la 2e ligne de la Figure Fusionner ci-dessous).
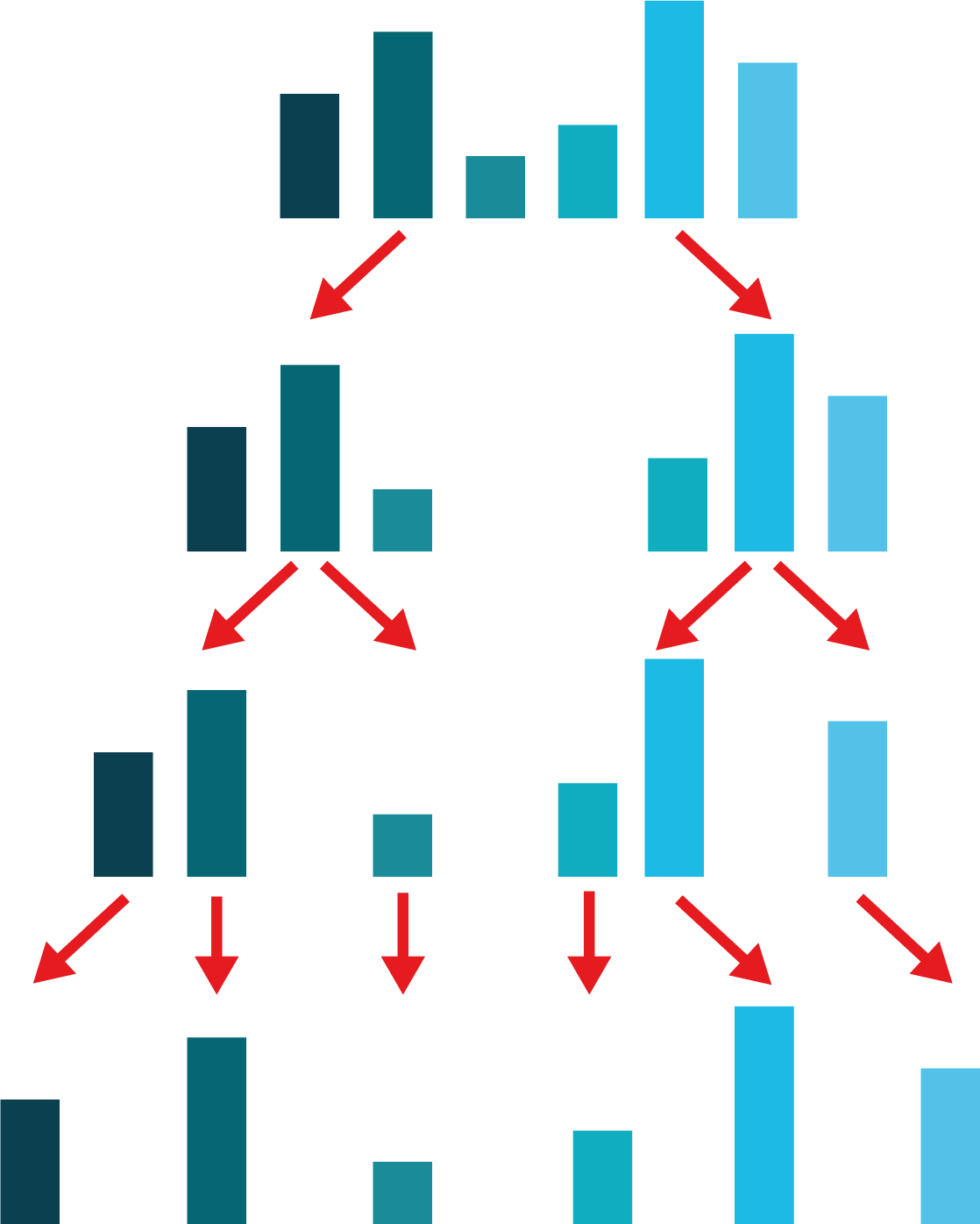
Diviser. Illustration de la première phase du tri fusion. A chaque étape le tableau est découpé en deux jusqu’à ce qu’il ne reste que des tableaux à 1 élément
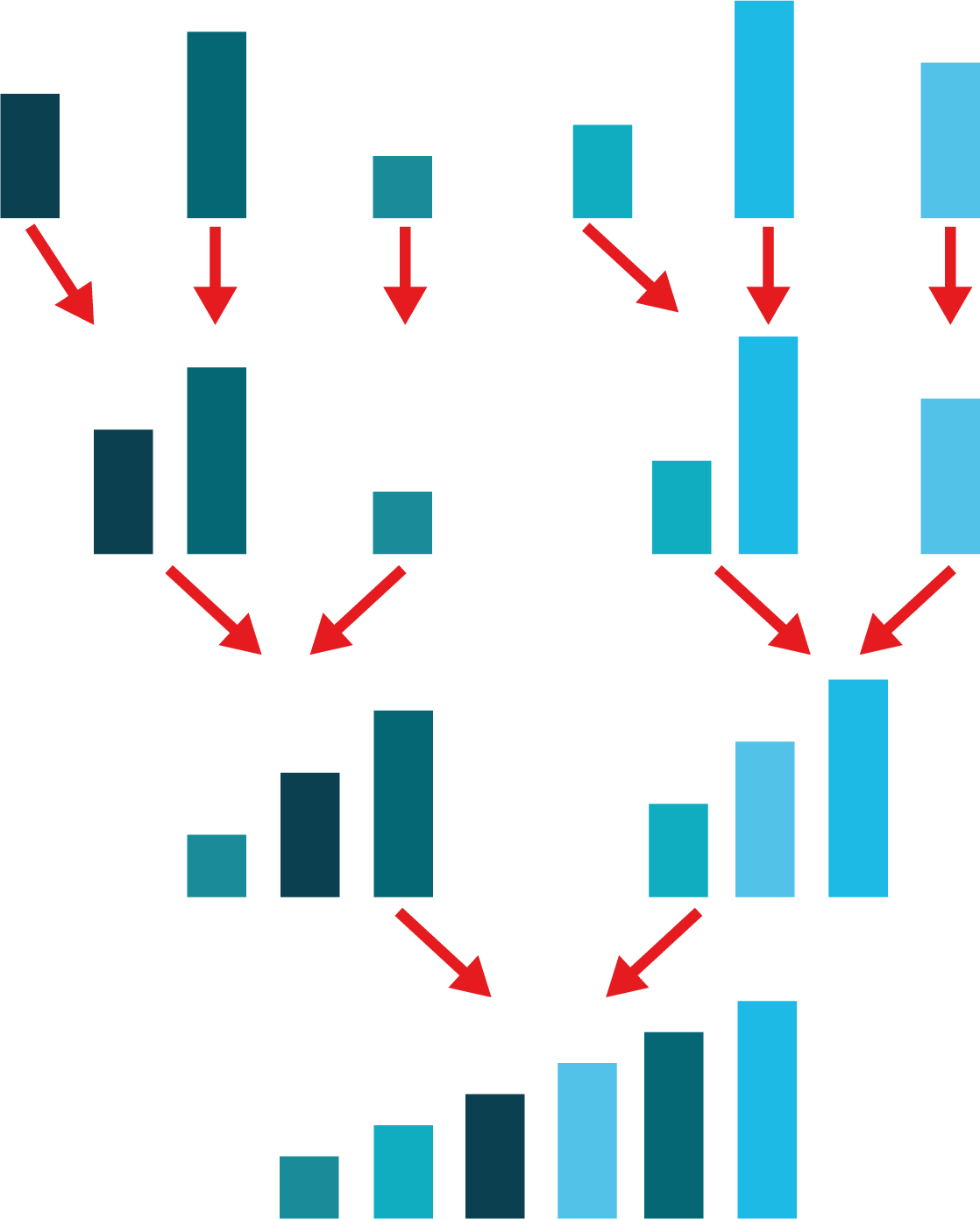
Fusionner. Illustration de la deuxième phase du tri fusion. A chaque étape les tableaux sont fusionnés par paires de deux, en faisant attention à respecter l’ordre de tri. On continue ainsi jusqu’à ce qu’il ne reste qu’un tableau unique
Dans les prochaines étapes (lignes 3 et 4 de la Figure Fusionner ci-dessus), on continue à fusionner les tableaux par paires de deux. Il est facile de fusionner ces tableaux, car ils sont déjà triés. Tout d’abord, on compare les premiers éléments des deux tableaux et on prend le plus petit des deux. Concrètement, on enlève le plus petit élément des deux tableaux pour commencer un nouveau tableau fusionné. On compare ensuite les premiers éléments des éléments restants dans les tableaux à fusionner et on prend à nouveau le plus petit des deux. On continue de la sorte jusqu’à ce qu’il ne reste pas d’éléments dans les tableaux à fusionner.
Chaque étape de la phase de fusion consiste à comparer deux éléments n fois, autant qu’il y a d’éléments à fusionner dans le tableau. Elle prend donc un temps qui grandit linéairement en fonction de la taille du tableau n. En tout il y a besoin de log(n) d’étapes ce qui nous donne l’ordre de complexité O(nlog(n)).
Le saviez-vous ?
Le tri rapide et le tri fusion se basent sur la stratégie algorithmique de résolution de problèmes « diviser pour régner ». Cette stratégie qui consiste à :
Diviser : décomposer le problème initial en sous-problèmes ;
Régner : résoudre les sous-problèmes ;
Combiner : calculer une solution au problème initial à partir des solutions des sous-problèmes.
Les sous-problèmes étant plus petits, ils sont plus faciles et donc plus rapides à résoudre. Les algorithmes de ce type sont efficaces et se prêtent à la résolution en parallèle (p.ex. multiprocesseurs).
Pour aller plus loin
La première question que l’on se pose lorsqu’on analyse un algorithme est son ordre de complexité. Si l’algorithme est trop lent, il ne sera pas utilisable dans la vie réelle. Lorsqu’on parle de complexité, on pense en fait à la complexité moyenne, mais on peut également calculer la complexité dans le meilleur et dans le pire cas.
Par exemple, si on trie un tableau qui est en fait déjà trié avec le tri par insertion, la complexité dans ce cas est linéaire ou O(n). Au contraire, si on trie ce même tableau avec le tri rapide, la complexité dans ce cas est quadratique ou O(n2). On voit donc que selon le tableau que l’on trie, le tri rapide peut être bien plus lent que le tri par insertion.
Une analyse complète d’un algorithme consiste à calculer la complexité non seulement dans le cas moyen, mais aussi dans le meilleur cas et dans le pire cas.
Une analyse complète va également calculer les constantes qui influencent l’ordre de complexité. Ces constantes ne sont pas importantes lors d’une première analyse d’un algorithme. En effet, les constantes n’ont que peu d’effet pour une grande taille des données n, c’est uniquement le terme qui grandit le plus rapidement en fonction de n qui compte, et qui figure dans un premier temps dans l’ordre de complexité. Par contre, lorsque l’on souhaite comparer deux algorithmes de la même complexité, il faut estimer les constantes et prendre celui des deux avec la plus petite constante.
Le saviez-vous ?
La complexité ne reflète pas la difficulté à implémenter un algorithme, comme on pourrait le croire, mais à quel point l’algorithme se complexifie au fur et à mesure que le nombre des entrées augmente. La complexité mesure le temps d’exécution d’un algorithme (ou sa rapidité) en termes du nombre d’instructions élémentaires exécutées en fonction de la taille des données. Mais est-ce que complexe veut dire la même chose que compliqué ? Une chose compliquée est difficile à saisir ou à faire, alors qu’une chose complexe est composée d’éléments avec de nombreuses interactions imbriquées.
Exercice 6 : comparaison de tris ✏️📒
Si une instruction prend 10-6 secondes, combien de temps faut-il pour trier un tableau d’1 million d’éléments avec le tri à sélection comparé au tri rapide (sans tenir compte de la constante) ?
Solution
Exercice 7 : tri rapide et pivot ✏️📒
Trier le tableau suivant avec l’algorithme de tri rapide : [3, 6, 8, 7, 1, 9, 4, 2, 5] à la main, en prenant le dernier élément comme pivot. Représenter l’état du tableau lors de toutes les étapes intermédiaires.
Est-ce que le choix du pivot est important ?
Solution
Exercice 8 : tri fusion ✏️📒
Trier le tableau suivant avec l’algorithme de tri fusion : [3, 6, 8, 7, 1, 9, 4, 2, 5] à la main. Représenter l’état du tableau lors de toutes les étapes intermédiaires.
N’y a-t-il qu’une seule solution ?
Solution
Exercice 9 : tri par selection ✏️📒
Trier le tableau suivant avec l’algorithme de tri par sélection : [3, 6, 8, 7, 1, 9, 4, 2, 5] à la main. Représenter l’état du tableau lors de toutes les étapes intermédiaires.
Solution
Exercice 10 : tri par insertion ✏️📒
Trier le tableau suivant avec l’algorithme de tri par insertion : [3, 6, 8, 7, 1, 9, 4, 2, 5] à la main. Représenter l’état du tableau lors de toutes les étapes intermédiaires.
Solution
Exercice 11 : tri à bulles ✏️📒
Trier le tableau suivant avec l’algorithme de tri à bulles : [3, 6, 8, 7, 1, 9, 4, 2, 5] à la main. Représenter l’état du tableau lors de toutes les étapes intermédiaires.
Exercice 12. Comparaison temporelle des algorithmes de tris 🔌
Créer une liste qui contient les valeurs de 1 à n dans un ordre aléatoire, où n prend la valeur 100, par exemple. Vous pouvez utiliser la fonction shuffle() du module random.
Implémenter au moins deux des trois algorithmes de tri vu au cours. A l’aide du module time et de sa fonction time(), chronométrez le temps prend le tri d’une liste de 100, 500, 1000, 10000, 20000, 30000, 40000 puis 50000 nombres.
Noter les temps obtenus et affichez-les sous forme de courbe dans un tableur. Ce graphique permet de visualiser le temps d’exécution du tri en fonction de la taille de la liste. Que constatez‑vous ?
Sur la base de ces mesures, pouvez-vous estimer le temps que prendrait le tri de 100000 éléments ?
Lancer votre programme avec 100000 éléments et comparez le temps obtenu avec votre estimation.